汪图南
LLM
LLM
LLM基础
名词缩写
LLM应用
RAG
Agent
Python技术栈
Python技术栈
快速入门
高级技巧
前端技术栈
前端技术栈
面试
前端面试之道
打包工具
Webpack
Rollup
TypeScript
TypeScript基础
TypeScript类型挑战
CSS预编译器
SASS
自动化测试
Vue应用测试
Vue源码分析
Vue源码分析
Vue2.0源码分析
Vue3.0源码分析
算法
算法
数据结构和算法(基础)
LeetCode(刷题)
书籍
书籍
JavaScript书籍
你不知道的JavaScript(上)
你不知道的JavaScript(中下)
JavaScript数据结构和算法
JavaScript设计模式与开发实践
深入理解ES6
Git书籍
精通Git
Github
介绍
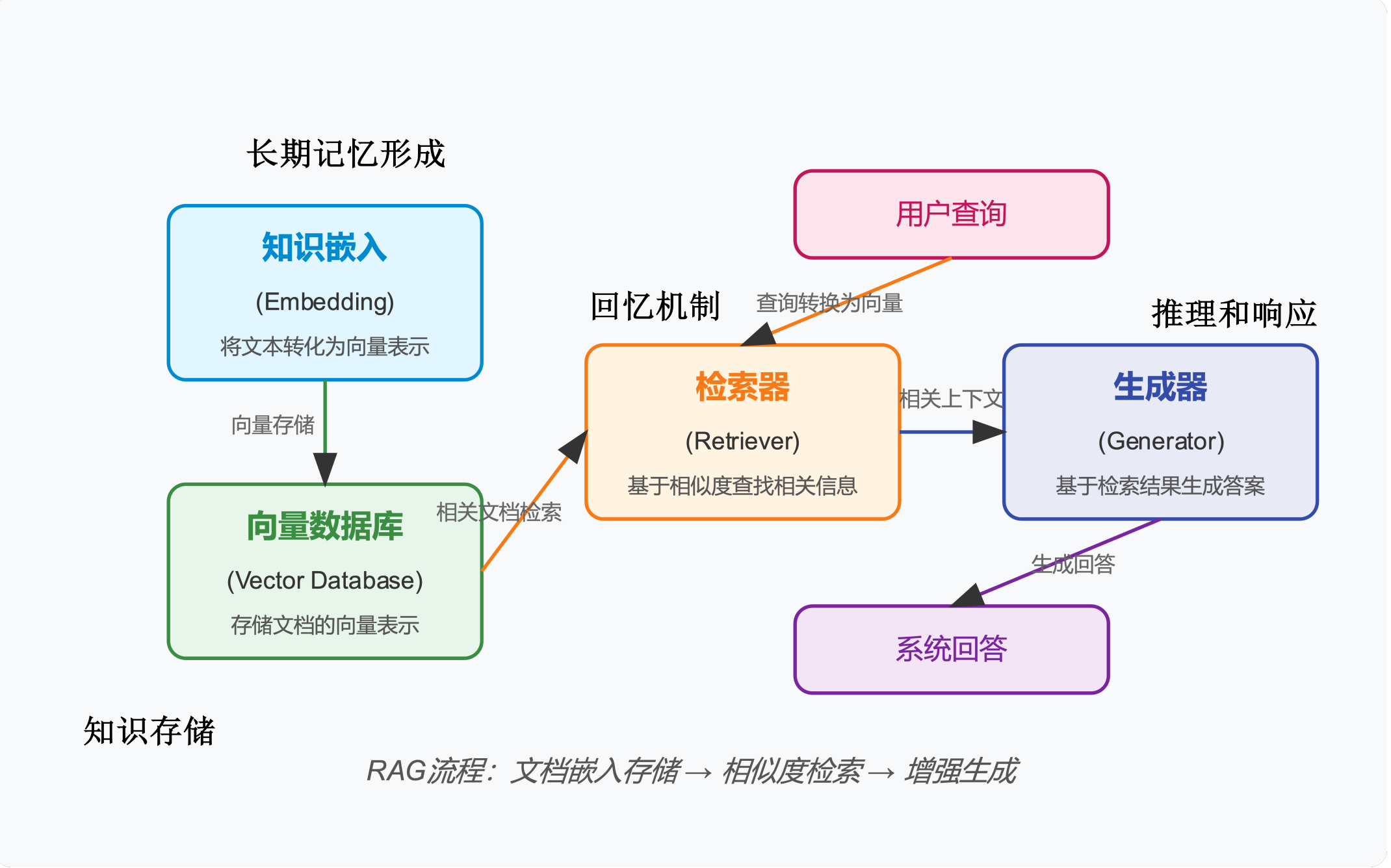
RAG
:Retrieval-Augmented Generation,检索增强生成,是大型语言模型(LLM)中的一种重要架构,它通过结合信息检索和文本生成来提高模型输出的准确性和相关性。